ORIGINAL RESEARCH
Can OpenAI ChatGPT Also Do Well on the ABFM ITE?
Phillip Kim, MD, MPH*, Jusel Ruelan, DO, Micheal Moya, MD
SAMC Department of Family Medicine Residency Program
*Principle Investigator
Click on each Section to Read
INTRO / BACKGROUND / PURPOSE
Introduction:
The development of artificial intelligence (AI) has a long history, dating back to the 1950s, when researchers explored the possibility of creating machines that could think and learn like humans. However, the field took a significant turn with the publication of a paper by researchers at Google's AI division in 2017. The paper outlined the Generative Pre-Trained Transformer (GPT) algorithm, which has revolutionized natural language processing tasks such as language modeling, text completion, and question-answering1. The GPT model works by breaking down the input text into tokens, which are then processed by a series of attention-based layers. The attention mechanism allows the model to focus on specific parts of the input text and to generate more accurate predictions. Hence the output of the GPT model is a sequence of probabilities for the next in input text. In recent times, Sam Altman, the developer and founder of OpenAI, has revolutionized the GPT model to democratize AI in mainstream markets. OpenAI's advancement in GPT has rapidly transformed diverse domains such as education, finance, and marketing. The technological prowess of GPT is evidenced by its mastery of standardized examinations including AP, Bar, and national medical licensure exams2.
Background:
The American Board of Family Medicine (ABFM) In-Training Examination (ITE) is a standardized test that has been administered since 1972. The purpose of the ABFM ITE is to assess the knowledge and progress of family medicine residents during their training. The exam is designed to help residents and program directors identify areas of strength and weakness in their training program, and to provide feedback to residents to help them prepare for the American Board of Family Medicine Certification Examination (ABFMCE) that they will take after completing their residency. The ABFM ITE is administered annually to all family medicine residents in accredited residency programs across the United States. The exam consists of 200 multiple-choice questions covering a broad range of topics in family medicine.
Purpose:
The purpose of this research case poster is to demonstrate and verify OpenAI's GPT model in its understanding of specific clinical questions in the setting of a standardized multiple choice question format given to family medicine residents and to further explore its implications to primary care medicine.
METHODS
We downloaded and extracted the 2022 ABFM ITE from the Resident Training Management System (RTMS) in PDF format. We utilized Python, a multi-purpose programming language, and its modules PyPDF2, Regex, and Pandas to parse the PDF into a manageable string format for dataframe columns containing 200 multiple questions and answers. Using OpenAI's API key, we iterated through each row column using Python and employed two GPT 3.5 models to complete each multiple-question formatted query: (1) text-davicini-003, noted for its ability to perform any language task with better quality, longer output, and consistent instruction-following than the curie, Babbage, or ada models, and (2) GPT-3.5-turbo, optimized for chat and costing 1/10th of the text-davinci-003 model.
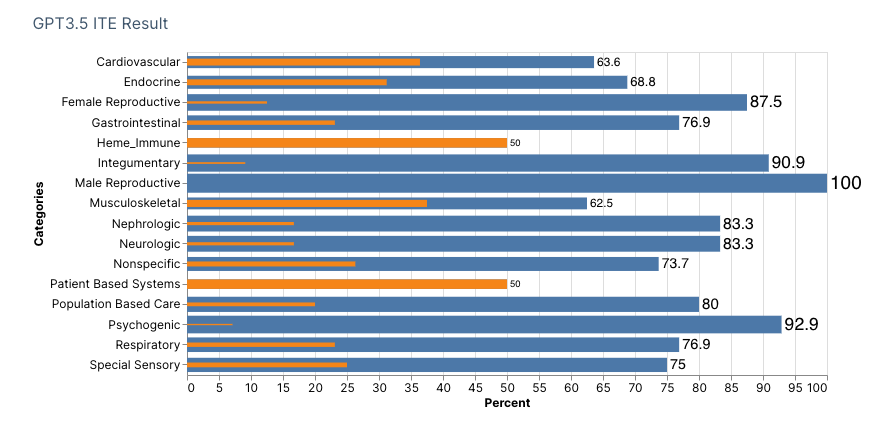
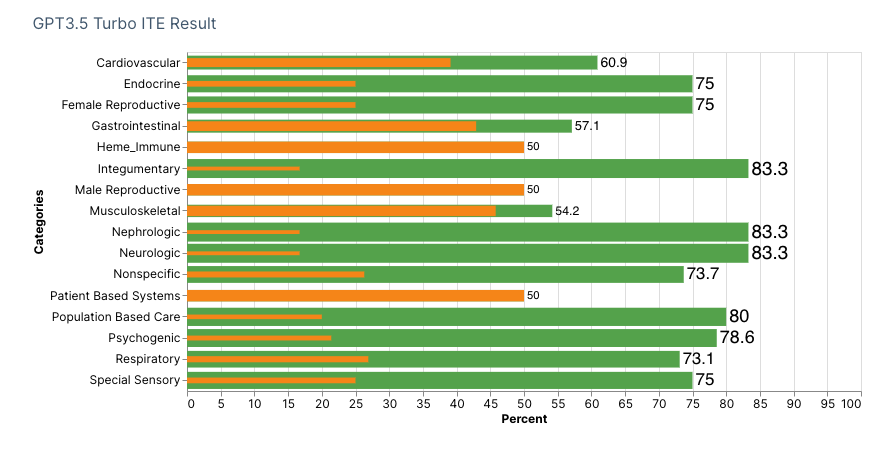
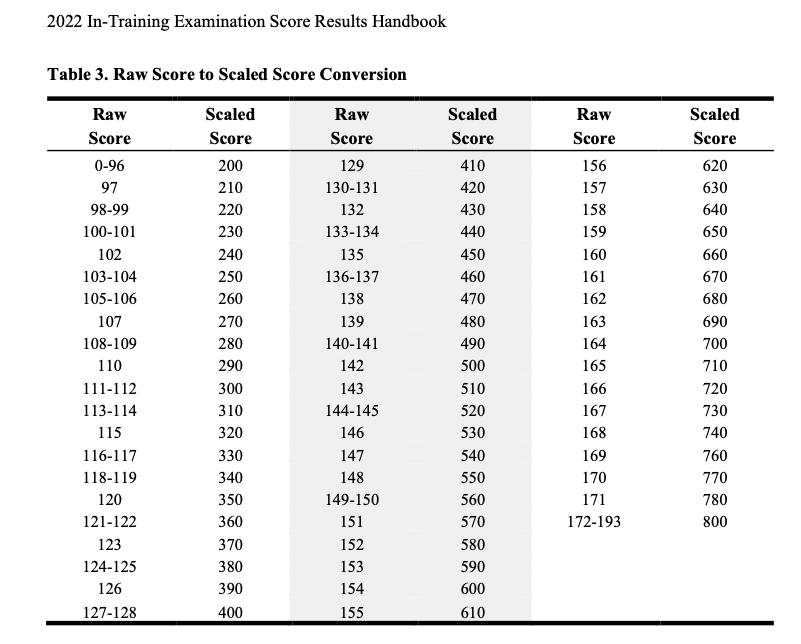
We entered GPT answers and cross-matched them against the given ABFM ITE answers labeled as True for Correct and False for Incorrect in an MS Excel spreadsheet. To analyze subject categories, we matched each question choice accordingly, as labeled in the 2022 ABFM ITE Handbook, and tallied Total Questions, Correct, Incorrect, and % Correct. For each GPT model, we obtained a scaled score using Table 3 of the 2022 ABFM ITE Handbook's Raw Score to Scaled Score Conversion. Of the 200 question items, items 21, 63, 97, 99, 138, 157, and 166 were excluded from scoring to follow ABFM's decision based on content and psychometric reasons. The final number of items scored was 193.
RESULTS
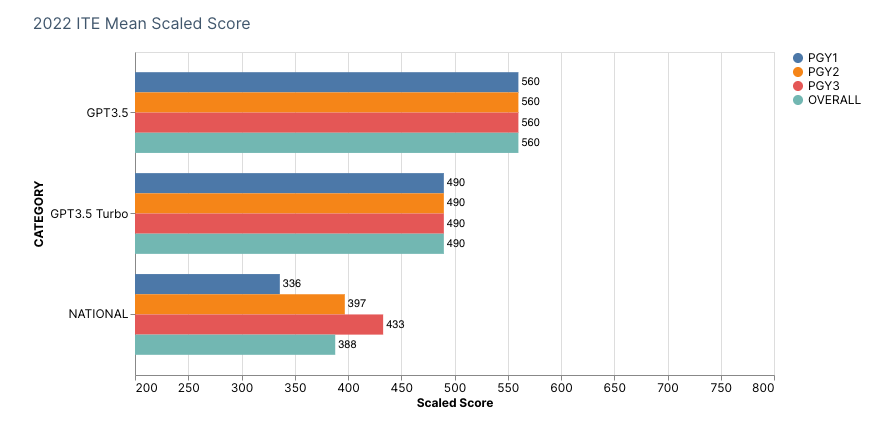
GPT3.5 and GPT3.5 Turbo successfully achieved a scaled score of 560 and 490 respectively, beating the national average of 388 on the 2022 ABFM In-Service Training Examination.