Can OpenAI ChatGPT Also Do Well on the ABFM ITE?
Phillip Kim, MD, MPH*, Jusel Ruelan, DO, Micheal Moya, MD
SAMC Department of Family Medicine Residency Program
*PrinciplePrincipal Investigator
Click on each Section to Read
INTRO / BACKGROUND / PURPOSE
Introduction:
The development of artificial intelligence (AI) has a long history, dating back to the 1950s, when researchers explored the possibility of creating machines that could think and learn like humans. However, the field took a significant turn with the publication of a paper by researchers at Google's AI division in 2017. The paper outlined the Generative Pre-Trained Transformer (GPT) algorithm, which has revolutionized natural language processing tasks such as language modeling, text completion, and question-answering1. The GPT model works by breaking down the input text into tokens, which are then processed by a series of attention-based layers. The attention mechanism allows the model to focus on specific parts of the input text and to generate more accurate predictions. Hence the output of the GPT model is a sequence of probabilities for the next in input text. In recent times, Sam Altman, the developer and founder of OpenAI, has revolutionized the GPT model to democratize AI in mainstream markets. OpenAI's advancement in GPT has rapidly transformed diverse domains such as education, finance, and marketing. The technological prowess of GPT is evidenced by its mastery of standardized examinations including AP, Bar, and national medical licensure exams2.
Background:
The American Board of Family Medicine (ABFM) In-Training Examination (ITE) is a standardized test that has been administered since 1972. The purpose of the ABFM ITE is to assess the knowledge and progress of family medicine residents during their training. The exam is designed to help residents and program directors identify areas of strength and weakness in their training program, and to provide feedback to residents to help them prepare for the American Board of Family Medicine Certification Examination (ABFMCE) that they will take after completing their residency. The ABFM ITE is administered annually to all family medicine residents in accredited residency programs across the United States. The exam consists of 200 multiple-choice questions covering a broad range of topics in family medicine.
Purpose:
The purpose of this research case poster is to demonstrate and verify OpenAI's GPT model in its understanding of specific clinical questions in the setting of a standardized multiple choice question format given to family medicine residents and to further explore its implications to primary care medicine.
METHODS
We downloaded and extracted the 2022 ABFM ITE from the Resident Training Management System (RTMS) in PDF format. We utilized Python, a multi-purpose programming language, and its modules PyPDF2, Regex, and Pandas to parse the PDF into a manageable string format for dataframe columns containing 200 multiple questions and answers. Using OpenAI's API key, we iterated through each row column using Python and employed two GPT 3.5 models to complete each multiple-question formatted query: (1) text-davicini-003, noted for its ability to perform any language task with better quality, longer output, and consistent instruction-following than the curie, Babbage, or ada models, and (2) GPT-3.5-turbo, optimized for chat and costing 1/10th of the text-davinci-003 model.
We entered GPT answers and cross-matched them against the given ABFM ITE answers labeled as True for Correct and False for Incorrect in an MS Excel spreadsheet. To analyze subject categories, we matched each question choice accordingly, as labeled in the 2022 ABFM ITE Handbook, and tallied Total Questions, Correct, Incorrect, and % Correct. For each GPT model, we obtained a scaled score using Table 3 of the 2022 ABFM ITE Handbook's Raw Score to Scaled Score Conversion. Of the 200 question items, items 21, 63, 97, 99, 138, 157, and 166 were excluded from scoring to follow ABFM's decision based on content and psychometric reasons. The final number of items scored was 193.
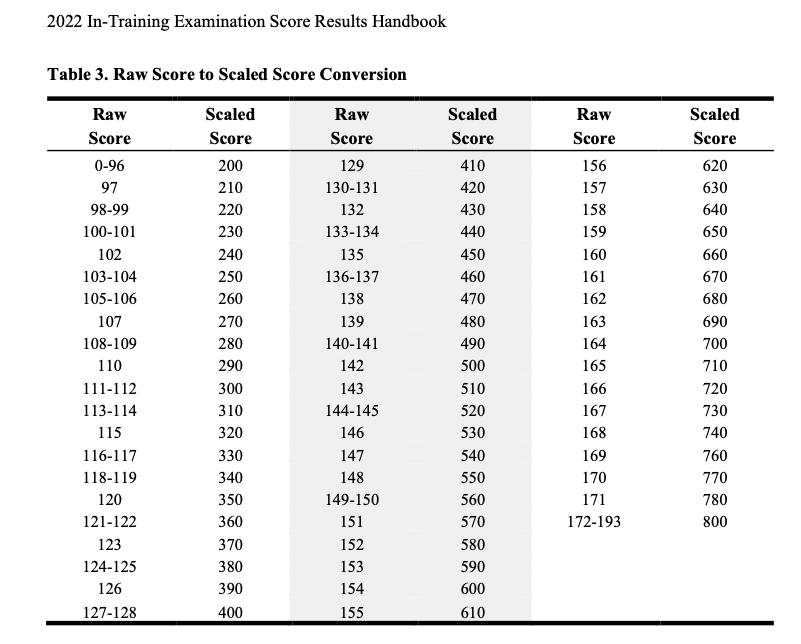
RESULTS
GPT3.5 and GPT3.5 Turbo successfully achieved a scaled score of 560 and 490 respectively, beating the national average of 388 on the 2022 ABFM In-Service Training Examination.
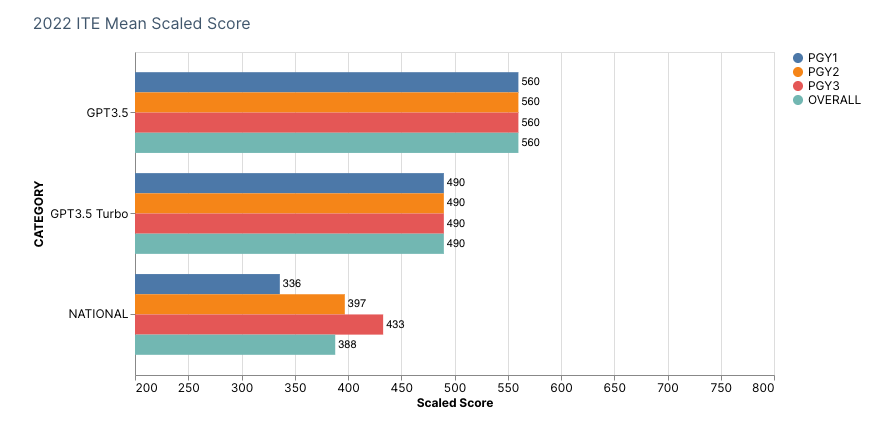
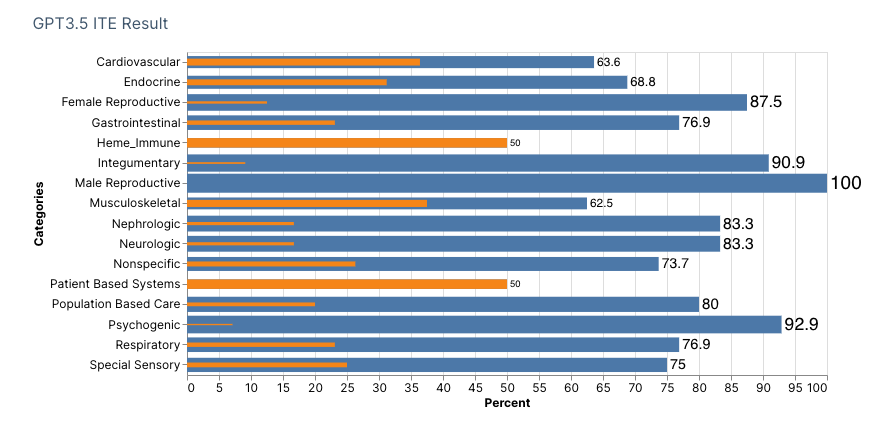
Using OpenAI’s first model text-davicini-003, we obtained an overall raw correct 144 items (SE: 0.036), incorrect raw 49 items (SE: 0.032), and raw percentage at 73% correct (95% CI: 0.676-0.816). In the second model using GPT-3.5-turbo, we obtained an overall raw correct 137 items (SE: 0.037), incorrect raw 56 items (SE: 0.033), and raw percentage at 68.5% correct (95% CI: 0.636-0.782). Using the 2022 ABFM ITE Handbook’s Raw Score to Scaled Score Conversion, a scaled score of 560 and 490 respectively for first and second models.
For our first model, relative categories of weakness were as follows:
- Hematology/Immunology
- Patient Based Systems
For our second model, relative categories of weakness were as follows:
- Gastrointestinal
- Male Reproductive
- Musculoskeletal
- Patient Based Systems
DISCUSSION / CONCLUSION
The results of OpenAI's GPT, using the first and second model integration, confirm its capabilities to answer very specific standardized examinations, including the 2022 ABFM ITE. However, the discrepancies and shortcomings, where scores were not 100% correct, are multifactorial. Foremost, OpenAI's GPT training model predates September 2021. This implies that any written question items with clinical practice changes/guidelines following September 2021 would be misled with incorrect responses. Second, the models trained could ONLY reply to responses without citations of specific clinical references, e.g. studies. OpenAI's technology is based on vectorized texts translated into tokens to closely match against an immense amount of scoured online data pool. The algorithm is NOT perfect at this time, where there is singularity and confirmed factuality based on query. Therefore, "hallucinations" can be of concern where GPT responses are exaggerated or incorrectly inferred.
The apparent 4.5% difference in raw percentage score between GPT3.5 text-davicni-003 and GTP-3.5-turbo could be most explained by possible runtime delay in query vectorized match responses against OpenAI's server data and how each model handles its vectorized match sequence. We expected GPT-3.5-turbo to be more reliable than the former, but we realized that OpenAI's training model can be off in correlative vector match predictions. We did not run multiple iterations of question items to determine the accuracy of responses, as our case study was to look at its first attempt in correctly answering the exam questions. This could be apparent for the relatively weak categories noted in the results versus not having enough data sources to respond correctly. We also realized that Items 10, 51, 117, 199, and 162 had images attached where both models do not have capabilities to interpret clinical images correctly. However, Item 162 was inferred and correctly answered by both models.
Using the Bayesian Score Predictor for successfully passing the initial ABFM Board Certification, both models would have near 100% pass rates given their SE and CI as noted for a scaled score of 560 for GPT3.5 text-davicni-003 and 490 for GTP-3.5-turbo, respectively.
REFERENCES
- Uszkoreit, J. (2017, August 31). Transformer: A Novel Neural Network Architecture for Language Understanding. Google AI Blog. https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html
- OpenAI. (2023). ChatGPT (Mar 14 version) [Large language model]. https://chat.openai.com/chat
SUPPLEMENTARY SECTIONS
PYTHON CODE TO CALL OPENAI API
import re
import pandas as pd
import openai
from api_secrets import API_KEY
import time
#OPEN RAW CSV DATA
df = pd.read_csv('questions.csv')
df = df.drop(df.columns[0], axis=1)
#FETCH API SECRET
openai.api_key = API_KEY
engines = ["gpt-3.5-turbo", "text-davinci-001"]
#USING GPT3.5 TURBO MODEL
#DEFINE API FUNCTION
def openai_turbo (question):
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
max_tokens=400,
messages=[
{"role": "user", "content": question}
]
)
time.sleep(5)
return completion.choices[0].message.content
#USING GPT3.5 DaVinci
#create a function to run each row and get answer wait 1sec response
def openai_response (question):
prompt = question
response = openai.Completion.create(engine=engines[2], prompt=prompt, max_tokens=400)
time.sleep(5) #change to 5 sec to answer
return response.choices[0].text
#apply GPT response function to each question and create df column with function eg. openai-turbo
df['GPT Answer'] = df['Question'].apply(openai_turbo)
#save OPENAI model to result CSV
df.to_csv('GPT_answers_turbo_result.csv')PYTHON CODE TO PARSE PDF INTO STRINGS
import re
import pandas as pd
import pdfplumber
import xlsxwriter
#Import PDF ITE ABFM and extract into TEXT format, remove special characters
question_file ="2022ITEMultChoice.pdf"
# open the PDF file
with pdfplumber.open(question_file) as pdf:
# Create an empty string to store the cleaned text
cleaned_text = ""
# get the number of pages in the PDF file
num_pages = len(pdf.pages)
# iterate over each page in the PDF file (except for the first page)
for i in range(1, num_pages):
# get the current page
page = pdf.pages[i]
# extract the text from the current page
text = page.extract_text()
# remove page numbers from the text
text = re.sub(r"\d+\s*$", "", text)
# Remove lines starting with "Item #"
lines = text.split("\n\n")
cleaned_lines = [line for line in lines if line and not line.startswith("Item #")]
text = "".join(cleaned_lines)
#Replace with .
text = text.replace("", '.')
cleaned_text += text
with open ('/Users/phillipkim/Downloads/ITE_Bank Extraction Method/PYTHON PDF Extraction Script/questions.txt', 'w') as f:
f.write(cleaned_text)
#Loop through each Question and separate out into Q/A dataframe format
df = pd.read_excel("FLEXI_QUIZ_Template.xlsx", header=1)
df = df.dropna()
df.columns
#create a regex pattern to separate out Q and answers and assign to individual column
pattern = r'(?<=\n)(?=\d+\. )'
result = re.split(pattern, cleaned_text)
data_row = {'Question Text': [],
'Question Type': 'Multiple Choice',
'Points Type': '',
'Question Points': '',
'Page \nNumber': '',
'Required': '',
'Question Feedback': '',
'Question Categories\n(separate each category with a comma)': '',
'Randomize Options': '',
'Option 1 Text': [],
'Option 1\nCorrect': '',
'Option 1\nPoints': '',
'Option 2 Text': [],
'Option 2\nCorrect': '',
'Option 2\nPoints': '',
'Option 3 Text': [],
'Option 3\nCorrect': '',
'Option 3\nPoints': '',
'Option 4 Text': [],
'Option 4\nCorrect': '',
'Option 4\nPoints': '',
'Option 5 Text': [],
'Option 5\nCorrect': '',
'Option 5\nPoints': '',
}
for i, section in enumerate(result):
split_text = re.split(r'\n(?=[A-E]\))', section)
#Append each value to the appropriate list in the data dict
#data_row['Page \nNumber'].append(i+1)
data_row['Question Text'].append(re.sub(r'^\d+\. ', '', split_text[0])if len(split_text) > 0 else None)
data_row['Option 1 Text'].append(re.sub(r'^[A-E]\)', '', split_text[1])if len(split_text) > 1 else None)
data_row['Option 2 Text'].append(re.sub(r'^[A-E]\)', '', split_text[2])if len(split_text) > 2 else None)
data_row['Option 3 Text'].append(re.sub(r'^[A-E]\)', '', split_text[3])if len(split_text) > 3 else None)
data_row['Option 4 Text'].append(re.sub(r'^[A-E]\)', '', split_text[4])if len(split_text) > 4 else None)
data_row['Option 5 Text'].append(re.sub(r'^[A-E]\)', '', split_text[5]) if len(split_text) > 5 else None)
new_df = pd.DataFrame(data_row)
df = pd.concat([df, new_df], ignore_index=True)
#new_df.to_csv('ITE2022.csv')
error_row = pd.concat([df.iloc[162], df.iloc[163]])